Scaling an old monolithic Django web app
Monolithic apps could be a challenge to scale, especially one that's ladden with technical debt. This is how we did it!
Written by Cho-Nan Tsai. Special thanks to Ben Limpanukorn.
The problem of growth
One of the biggest challenges of maintaining a tech stack is to ensure that tech debt is kept to the minimum so that it doesn't get in the way of new feature development. At Camino Financial, we are heavily invested in Python. We have software written in Python in the following areas: backend, serverless and data analytics. Our very first project was written using the Django framework and has grown large over the course of several years. Django is a nice framework to help get things started and to iterate versions quickly. We did exactly that the first year or two. However, the software evolved to become a monolithic application. While we found pockets of time to decouple modules and clean up tech debt, we are simply too busy with shipping new features.
The problem became a lot more pronounced when we started adding more users and asynchronous tasks to our system. Things got so bad when the system average load started looking ridiculous:

Since all initial setup was in 1 AWS VM, this led to Nginx timeouts and high latency on page loads.
Brainstorming
We discussed a few possible approaches to this problem. Initially, we toyed with extracting some of the more heavy-duty modules and converting them to serverless (Serverless Framework). That was proven to be too difficult since some of the modules were very tightly coupled. Similarly, we thought a microservice solution would be great but again -- the modules were too tightly coupled.
We also discussed the possibility of using a load balancer in front of the VMs to distribute the load. However, this got shot down as well since with our set-up this would lead to a database race condition.
At the end, we decided to have 2 servers, one (Back Office) for handling user requests and the other for handling asynchronous tasks (Async Server). This post talks about our solution discovery journey.
Version 1.0
Our initial version involves expanding our current CICD pipeline to trigger the building of the Docker containers for each of the servers and then deploying them to our AWS VM. At the high-level, we are still leveraging automated tests to run with manual approval before deploying to production. On top of that, we are also modifying the source code before deploying for the asynchronous task server (bo-common), setting Elastic IP address and then terminating the old stack. Sounds terrific, right? No, absolutely disastrous.
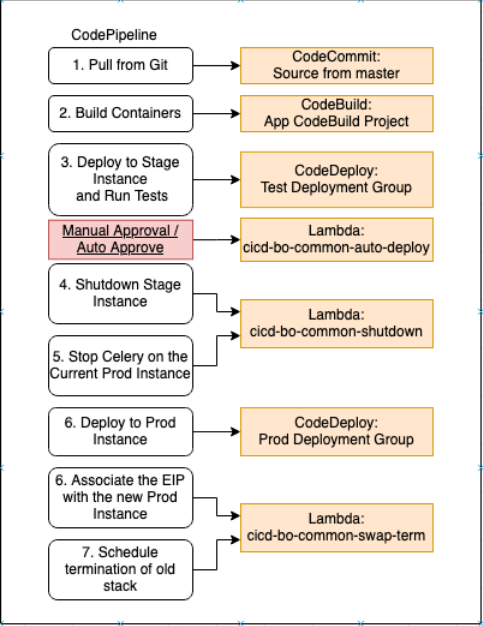
The problem with the set-up is that it tries to do too much in the deployment process and it has interfered with our production server on several occasions. The main points of failures included: Duplicated Django configurations in both VM instances, which becomes confusing for developers. Multiple lambda serverless end points trying to keep things in sync. This ran into synchronization issues when developers committed code in close successions. Implementing auto approve and manual approve creates confusion for developers Spinning up new stacks and assigning elastic IP was not a good approach (load balancer would have been better). Maintaining 2 repositories that are almost identical. Sometimes old servers do not get terminated, leading to waste and unnecessary tasks running in parallel. Almost identical repos (one for the main server and the other for the async task server) being synchronized by lambda.
However, when things are working, it does what it is supposed to do -- relieving the load on the main server when things are running asynchronously. However, we decide to iterate on this to make things simpler.
Version 2.0
Eventually, we decide to address the issues by having another iteration with our CICD pipeline design. First, we revert to the original pipeline which is a lot cleaner and straightforward. Then we make a key change to preserve the code but introduce a mini fork in our prod CICD pipeline, one for Back Office and another for Async Server. The nice thing about this approach is that we longer need multiple lambda functions for code synching and deployment. Everything is triggered from the top when the repository is updated. The only thing that’s different between the code deployed in each VM is the configuration file. This makes things a lot easier to manage for developers.
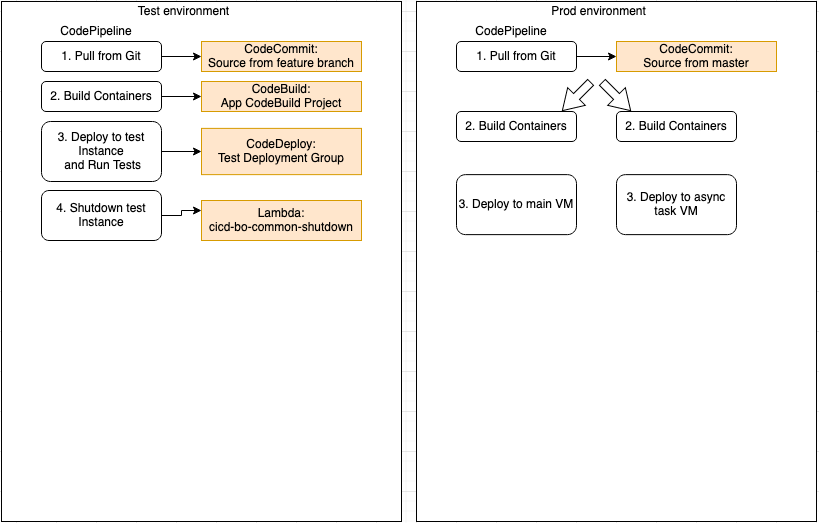
Conclusion
It’s been months since we deployed this new set up. Fortunately, things have been fairly stable. We have deprecated some of the lambda functions that are no longer needed and killed the ‘identical’ repo. For future improvements, we are contemplating introducing priority queues within the Async Server set-up so that tasks can be processed according to the priority assigned.